Check your requirements.txt
NEW
Based on project statistics from the GitHub repository for the PyPI package accel-brain-base, we found that it has been starred 320 times.

We noticed that this project uses a license which requires less permissive conditions such as disclosing the source code, stating changes or redistributing the source under the same license. It is advised to further consult the license terms before use.
We found a way for you to contribute to the project! Looks like accel-brain-base is missing a security policy.
You can connect your project's repository to Snyk to stay up to date on security alerts and receive automatic fix pull requests.
Keep your project free of vulnerabilities with SnykFurther analysis of the maintenance status of accel-brain-base based on released PyPI versions cadence, the repository activity, and other data points determined that its maintenance is Inactive.
An important project maintenance signal to consider for accel-brain-base is that it hasn't seen any new versions released to PyPI in the past 12 months, and could be considered as a discontinued project, or that which receives low attention from its maintainers.
In the past month we didn't find any pull request activity or change in issues status has been detected for the GitHub repository.
This project has seen only 10 or less contributors.
We found a way for you to contribute to the project! Looks like accel-brain-base is missing a Code of Conduct.
accel-brain-base is a basic library of the Deep Learning for rapid development at low cost. This library makes it possible to design and implement deep learning, which must be configured as a complex system or a System of Systems, by combining a plurality of functionally differentiated modules such as a Restricted Boltzmann Machine(RBM), Deep Boltzmann Machines(DBMs), a Stacked-Auto-Encoder, an Encoder/Decoder based on Long Short-Term Memory(LSTM), and a Convolutional Auto-Encoder(CAE).
From the view points of functionally equivalents and structural expansions, this library also prototypes many variants such as energy-based models and Generative models. Typical examples are Generative Adversarial Networks(GANs) and Adversarial Auto-Encoders(AAEs).
It also supports the implementation of Semi-Supervised Learning and Self-Supervised Learning, which consists of a combination of supervised and unsupervised learning systems. This library dryly considers the various Transformers variants such as BERT, XLNet, RoBERTa, ALBERT, etc, are merely applications of Self-Supervised Learning or Self-Supervised Domain Adaptation(SSDA). From this point of view, this class builds the Transformers variants as SSDA models.
In addition, this library provides Deep Reinforcement Learning such as Deep Q-Networks that applies the neural network described above as a function approximator. In principle, any neural network described above can be implemented as a function approximator.
See also ...
accel-brain-base to build the Encoder/Decoder controllers, Attention models, or Transformer models.accel-brain-base as a Function Approximator.accel-brain-base as components for Generative models based on the Statistical machine learning problems.accel-brain-base as components for Generative models based on the Statistical machine learning problems.Install using pip:
pip install accel-brain-base
or,
python setup.py bdist_wheel
pip install dist/accel_brain_base-*.*.*-py3-*-*.whl
The source code is currently hosted on GitHub.
Installers for the latest released version are available at the Python package index.
In the Apache MXNet version of this library, almost all models inherit HybridBlock from mxnet.gluon. Functions for common ML Ops such as saving and loading parameters are provided by HybridBlock.
On the other hand, in PyTorch of this library, almost all models inherit Module from torch.nn. Check the official documentation for the information you need.
Full documentation is available on https://code.accel-brain.com/Accel-Brain-Base/README.html. This document contains information on functionally reusability, functional scalability and functional extensibility.
How the Research and Development(R&D) on the subject of machine learning including deep learning, after the era of "Democratization of Artificial Intelligence(AI)", can become possible? Simply implementing the models and algorithms provided by standard machine learning libraries and applications like AutoML would reinvent the wheel. If you just copy and paste the demo code from the library and use it, your R&D would fall into dogmatically authoritarian development, or so-called the Hype driven development.
If you fall in love with the concept of "Democratization of AI," you may forget the reality that the R&D is under the influence of not only democracy but also capitalism. The R&D provides economic value when its R&D artifacts are distinguished from the models and algorithms realized by standard machine learning libraries and applications such as AutoML. In general terms, R&D must provide a differentiator to maximize the scarcity of its implementation artifacts.
On the other hand, it must be remembered that any R&D builds on the history of the social structure and the semantics of the concepts envisioned by previous studies. Many models and algorithms are variants derived not only from research but also from the relationship with business domains. It is impossible to assume differentiating factors without taking commonality and identity between society and its history.
Considering many variable parts, structural unions, and functional equivalents in the deep learning paradigm, which are variants derived not only from research but also from the relationship with business domains, from perspective of commonality/variability analysis in order to practice object-oriented design, this library provides abstract classes that define the skeleton of the deep Learning algorithm in an operation, deferring some steps in concrete variant algorithms such as the Deep Boltzmann Machines, Stacked Auto-Encoder, Encoder/Decoder based on LSTM, and Convolutional Auto-Encoder to client subclasses. The abstract classes and the interfaces in this library let subclasses redefine certain steps of the deep Learning algorithm without changing the algorithm's structure.
These abstract classes can also provide new original models and algorithms such as Generative Adversarial Networks(GANs), Deep Reinforcement Learning, or Neural network language model by implementing the variable parts of the fluid elements of objects.
The functions of Deep Learning are already available in many machine learning libraries. Broadly speaking, the deep learning functions provided by each machine learning library can be divided into the following two.
Many of the former have somewhat fixed error functions, initialization strategies, samplers, activation functions, regularization, and deep architecture configurations. That is, the functional extensibility is low. If you just want to run a distributed batch program or demo code, or just run it on a pre-designed interface, you should be fine with these components.
But, in-house R&D aimed at extending to more accurate and faster algorithms, it is a risk to rely on distributions that are less functionally reusable and less functionally scalable. In addition, many of the "A component that works just by running a batch program or API" tend to be specified with the condition that "if you prepare an appropriate dataset, it will work". The "appropriateness" of the "appropriate dataset" is often undecidable without knowing the inside of the black box obscured by its components.
On the other hand, in the existing machine learning library, the latter "A component that allows you to freely design its functions and algorithms" is certainly distributed. For example, MxNet/Gluon's HybridBlock gives you the freedom to design functions. Similar things can be done with PyTorch's torch.nn.
However, it cannot be said that a single algorithm can be produced in-house simply by making full use of these components. In-house R&D is also an organizational decision-making process. In this procedure, problems that can be solved by machine learning and statistics are first set in order to meet the demands from the business domain. Then, we will design an algorithm that functions as a problem-solving solution to this problem setting.
However, it cannot be said that there is only one function as a problem solution. Unless we compare several functionally equivalent algorithms that help solve the problem, it remains unclear which algorithm should be the final choice.
From perspective of commonality/variability analysis in order to practice object-oriented design, the concepts and interfaces of Deep Learning paradigms can be organized as follows:

ExtractableData is an interface responsible for extracting data from local files.NoiseableData is an interface that has the function of enhancing robustness by adding noise to the extracted sample.IteratableData is an interface that has the function of repeatedly outputting labeled and unlabeled samples by calling a class that implements ExtractableData. This function is the heart of iterative learning algorithms such as stochastic gradient descent. Whether or not to put the data in GPU memory can be selected in this subclass.SamplableData is a useful interface for introducing neural network learning algorithms into data sampling processing, especially for Generative Adversarial Networks(GANs).ObservableData is an interface for implementing neural network models in general. All of these subclasses are designed with the assumption that IteratableData will be delegated. You can also observe the mini-batch data extracted by SamplableData. Of course, the input / output function is variable depending on the problem setting, but basically it executes inference for the observed data points. The presence or absence of hyperparameters and GPUs can be adjusted in this subclass.ComputableLoss is nothing but an interface for error/loss functions. Each subclass is premised on the automatic differentiation function implemented in the machine learning library.RegularizatableData is the interface for performing regularization. The amount that the regular term is given as a penalty term can be realized inside the forward propagation method or inside the error/loss function. This interface works when other special regularizations are performed immediately after parameter updates.ControllableModel functions as a controller when implementing complex ObservableData in combination as a complex system(or System of Systems) such as deep reinforcement learning and hostile generation network.Broadly speaking, each subclass that implements these interfaces is considered functionally equivalent and mutually substitutable. For example, the following classes are implemented as subclasses of ObservableData.
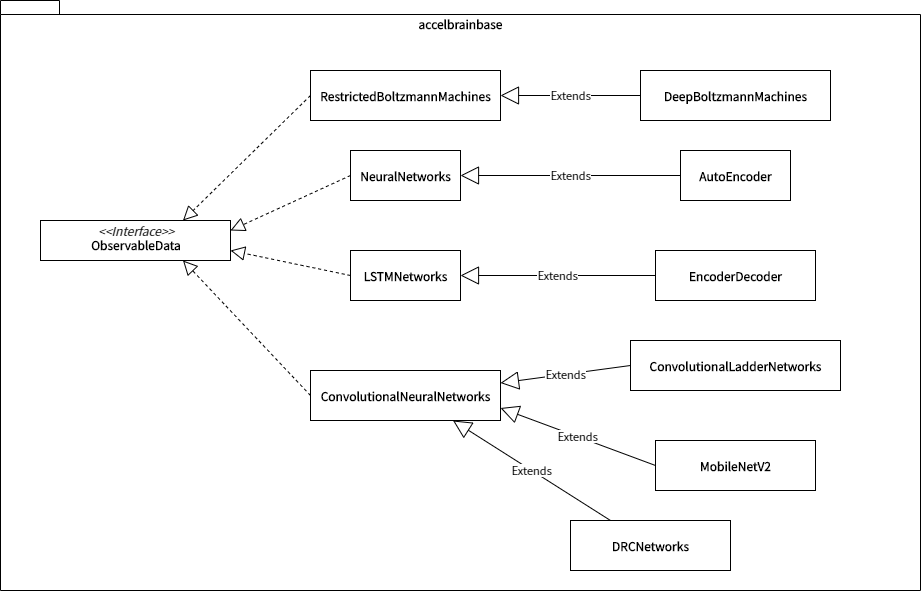
For example, Neural Networks makes it possible to build multi-layer neural networks. And, after inheriting this class, AutoEncoder constructed by joining two NeuralNetworkss in a stack is placed. There is a similar relationship between LSTMNetworks for building LSTM(Long short-term memory) Networks, which is a type of Recurrent Neural Networks, and its subclass EncoderDecoder.
In addition, various subclasses are arranged for ConvolutionalNeuralNetworks, which builds convolutional neural networks. Many relatively new learning algorithms, such as semi-supervised learning and self-supervised learning, have been proposed as extensions of convolutional neural networks. Therefore, when these algorithms are implemented, they are often implemented as a subclass of ConvolutionalNeuralNetworks.
When adopting a functionalism, such a series of interface designs assists in the search for functional equivalents. Since each class that realizes the same interface is designed on the premise of the same interface specifications, it is easy to consider it as a candidate for functional equivalent.
Furthermore, developers using this library can reduce the burden of functional expansion as well as searching for functional equivalents. In fact, there are functional extensions to this library.
For example, Automatic Summarization Library: pysummarization, which realizes automatic document summarization by natural language processing and text mining, reuses the Sequence-to-Sequence (Seq2Seq) model realized by accel-brain-base. This sub-library makes it possilbe to do automatically document summarization and clustering based on the manifold hypothesis.
On the other hand, in Reinforcement Learning Library: pyqlearning and Generative Adversarial Networks Library: pygan, Reinforcement Learning and various variants of GANs are implemented.
Let's exemplify the basic deep architecture that this library has already designed. Users can functionally reuse or functionally extend the already implemented architecture.
The function of this library is building and modeling Restricted Boltzmann Machine(RBM) and Deep Boltzmann Machine(DBM). The models are functionally equivalent to stacked auto-encoder. The basic function is the same as dimensions reduction or pre-learning for so-called transfer learning.
 | 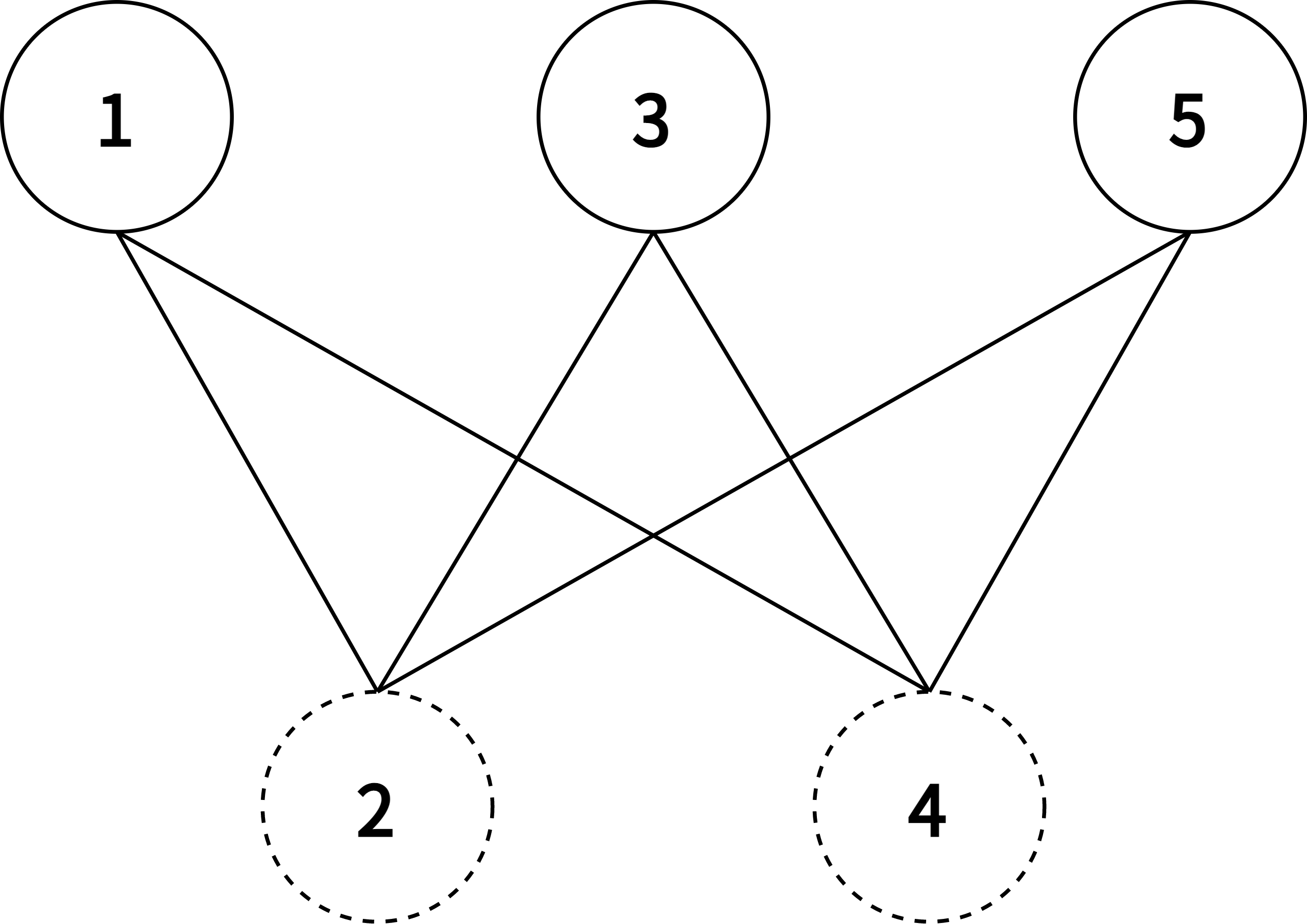 |
| Boltzmann Machine | Restricted Boltzmann Machine |
According to graph theory, the structure of RBM corresponds to a complete bipartite graph which is a special kind of bipartite graph where every node in the visible layer is connected to every node in the hidden layer. Based on statistical mechanics and thermodynamics(Ackley, D. H., Hinton, G. E., & Sejnowski, T. J. 1985), the state of this structure can be reflected by the energy function:
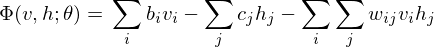
where 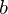 is a bias in visible layer,
is a bias in visible layer,  is a bias in hidden layer,
is a bias in hidden layer, 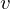 is an activity or a state in visible layer,
is an activity or a state in visible layer, 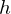 is an activity or a state in hidden layer, and
is an activity or a state in hidden layer, and 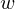 is a weight matrix in visible and hidden layer. The activities can be calculated as the below product, since the link of activations of visible layer and hidden layer are conditionally independent.
is a weight matrix in visible and hidden layer. The activities can be calculated as the below product, since the link of activations of visible layer and hidden layer are conditionally independent.
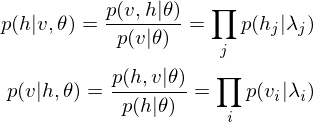
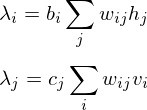
Because of the rules of conditional independence, the learning equations of RBM can be introduced as simple form. The distribution of visible state which is marginalized over the hidden state is as following:
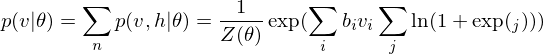
where 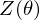 is a partition function in statistical mechanics or thermodynamics. Let
is a partition function in statistical mechanics or thermodynamics. Let  be set of observed data points, then
be set of observed data points, then 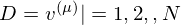 . Therefore the gradients on the parameter
. Therefore the gradients on the parameter 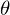 of the log-likelihood function are
of the log-likelihood function are
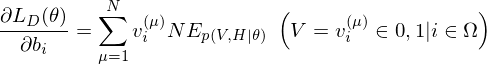

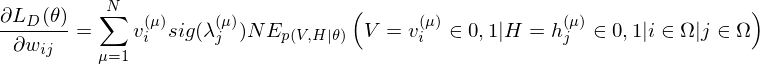
where 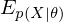 is an expected value for
is an expected value for 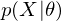 .
. 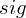 is a sigmoid function.
is a sigmoid function.
The learning equations of RBM are introduced by performing control so that those gradients can become zero.
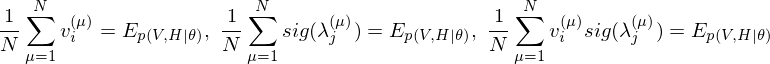

In relation to RBM, Contrastive Divergence(CD) is a method for approximation of the gradients of the log-likelihood(Hinton, G. E. 2002). The procedure of this method is similar to Markov Chain Monte Carlo method(MCMC). However, unlike MCMC, the visbile variables to be set first in visible layer is not randomly initialized but the observed data points in training dataset are set to the first visbile variables. And, like Gibbs sampler, drawing samples from hidden variables and visible variables is repeated k times. Empirically (and surprisingly), k is considered to be 1.

As is well known, DBM is composed of layers of RBMs stacked on top of each other(Salakhutdinov, R., & Hinton, G. E. 2009). This model is a structural expansion of Deep Belief Networks(DBN), which is known as one of the earliest models of Deep Learning(Le Roux, N., & Bengio, Y. 2008). Like RBM, DBN places nodes in layers. However, only the uppermost layer is composed of undirected edges, and the other consists of directed edges. DBN with R hidden layers is below probabilistic model:
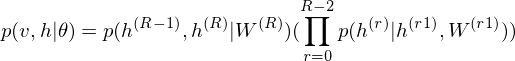
where r = 0 points to visible layer. Considerling simultaneous distribution in top two layer,
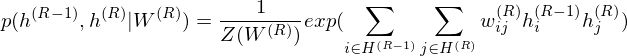
and conditional distributions in other layers are as follows:
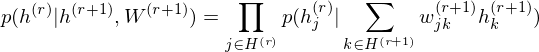
The pre-learning of DBN engages in a procedure of recursive learning in layer-by-layer. However, as you can see from the difference of graph structure, DBM is slightly different from DBN in the form of pre-learning. For instance, if r = 1, the conditional distribution of visible layer is
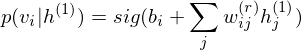 .
.On the other hand, the conditional distribution in the intermediate layer is
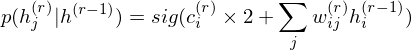
where 2 has been introduced considering that the intermediate layer r receives input data from Shallower layer
r-1 and deeper layer r+1. DBM sets these parameters as initial states.
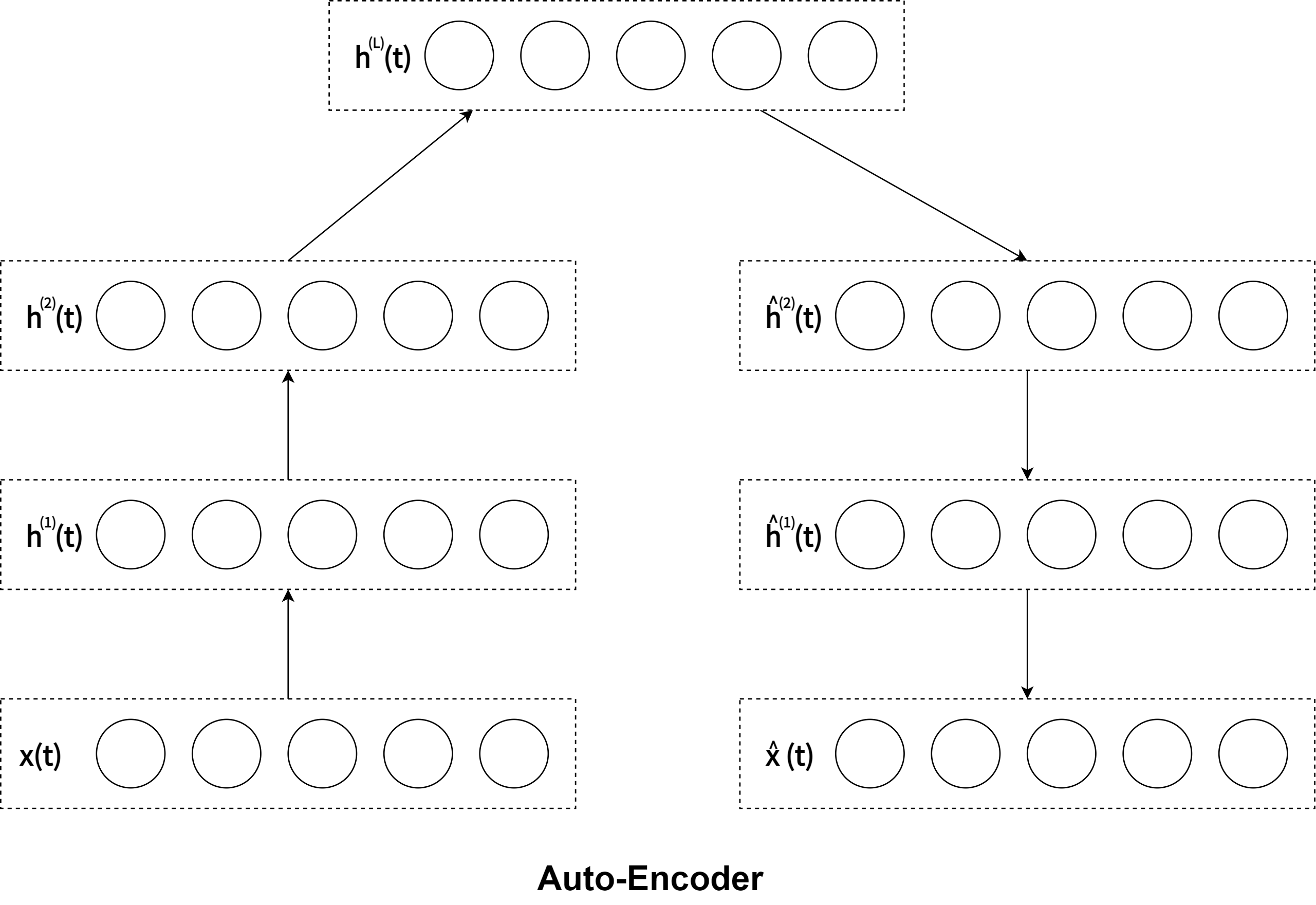
DBM is functionally equivalent to a Stacked Auto-Encoder, which is-a neural network that tries to reconstruct its input. To encode the observed data points, the function of DBM is as linear transformation of feature map below
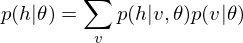 .
.On the other hand, to decode this feature points, the function of DBM is as linear transformation of feature map below
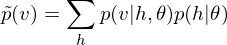 .
.The reconstruction error should be calculated in relation to problem setting such as the Representation Learning. In default, this library computes Mean Squared Error(MSE) or L2 norm. For instance, my jupyter notebook: demo/Deep-Boltzmann-Machines-for-Representation-Learning.ipynb demonstrates that DBM which is a Stacked Auto-Encoder can minimize the reconstruction errors based on the Representation Learning.
The methodology of equivalent-functionalism enables us to introduce more functional equivalents and compare problem solutions structured with different algorithms and models in common problem setting. For example, in dimension reduction problem, the function of Encoder/Decoder schema is equivalent to DBM as a Stacked Auto-Encoder.
According to the neural networks theory, and in relation to manifold hypothesis, it is well known that multilayer neural networks can learn features of observed data points and have the feature points in hidden layer. High-dimensional data can be converted to low-dimensional codes by training the model such as Stacked Auto-Encoder and Encoder/Decoder with a small central layer to reconstruct high-dimensional input vectors. This function of dimensionality reduction facilitates feature expressions to calculate similarity of each data point.
This library provides Encoder/Decoder based on LSTM, which is a reconstruction model and makes it possible to extract series features embedded in deeper layers. The LSTM encoder learns a fixed length vector of time-series observed data points and the LSTM decoder uses this representation to reconstruct the time-series using the current hidden state and the value inferenced at the previous time-step.
One interesting application example is the Encoder/Decoder for Anomaly Detection (EncDec-AD) paradigm (Malhotra, P., et al. 2016). This reconstruction model learns to reconstruct normal time-series behavior, and thereafter uses reconstruction error to detect anomalies. Malhotra, P., et al. (2016) showed that EncDec-AD paradigm is robust and can detect anomalies from predictable, unpredictable, periodic, aperiodic, and quasi-periodic time-series. Further, they showed that the paradigm is able to detect anomalies from short time-series (length as small as 30) as well as long time-series (length as large as 500).
As the prototype is exemplified in demo/Encoder-Decoder-based-on-LSTM-for-Anomaly-Detection.ipynb, this library provides Encoder/Decoder based on LSTM as a EncDec-AD scheme.
Convolutional Auto-Encoder(Masci, J., et al., 2011) is a functionally equivalent of Stacked Auto-Encoder in relation to problem settings such as image segmentation, object detection, inpainting and graphics. A stack of Convolutional Auto-Encoder forms a convolutional neural network(CNN), which are among the most successful models for supervised image classification. Each Convolutional Auto-Encoder is trained using conventional on-line gradient descent without additional regularization terms.

Image in the Weizmann horse dataset.

Reconstructed image by Convolutional Auto-Encoder.
This library can draw a distinction between Stacked Auto-Encoder and Convolutional Auto-Encoder, and is able to design and implement respective models. Stacked Auto-Encoder ignores the 2 dimentional image structures. In many cases, the rank of observed tensors extracted from image dataset is more than 3. This is not only a problem when dealing with realistically sized inputs, but also introduces redundancy in the parameters, forcing each feature to be global. Like Shape-BM, Convolutional Auto-Encoder differs from Stacked Auto-Encoder as their weights are shared among all locations in the input, preserving spatial locality. Hence, the reconstructed image data is due to a linear combination of basic image patches based on the latent code.
In this library, Convolutional Auto-Encoder is also based on Encoder/Decoder scheme. The encoder is to the decoder what the Convolution is to the Deconvolution. The Deconvolution also called transposed convolutions "work by swapping the forward and backward passes of a convolution." (Dumoulin, V., & Visin, F. 2016, p20.)
In relation to the Representation Learning, like DBM, this model also can minimize the reconstruction errors. An example can be found in demo/Convolutional-Auto-Encoder-for-Representation-Learning.ipynb.
This library also provides some functionally equivalents of the Convolutional Auto-Encoder. For instance, Convolutional Contractive Auto-Encoder(Contractive CAE) is a Convolutional Auto-Encoder based on the First-Order Contractive Auto-Encoder(Rifai, S., et al., 2011), which executes the representation learning by adding a penalty term to the classical reconstruction cost function. This penalty term corresponds to the Frobenius norm of the Jacobian matrix of the encoder activations with respect to the input and results in a localized space contraction which in turn yields robust features on the activation layer.
Analogically, the Contractive Convolutional Auto-Encoder calculates the penalty term. But it differs in that the operation of the deconvolution intervenes insted of inner product. The prototype is exemplified in demo/Contractive-Convolutional-Auto-Encoder-for-Representation-Learning.ipynb.
Auto-Encoders, such as the Encoder/Decoder, the Convolutional Auto-Encoder, and the DBM have in common that these models are Stacked Auto-Encoders or the reconstruction models. On the other hand, the Auto-Encoders and the Encoder/Decoders are not statistical mechanical energy-based models unlike with RBM or DBM.
However, Auto-Encoders have traditionally been used to represent energy-based models. According to the statistical mechanical theory for energy-based models, Auto-Encoders constructed by neural networks can be associated with an energy landscape, akin to negative log-probability in a probabilistic model, which measures how well the Auto-Encoder can represent regions in the input space. The energy landscape has been commonly inferred heuristically, by using a training criterion that relates the Auto-Encoder to a probabilistic model such as a RBM. The energy function is identical to the free energy of the corresponding RBM, showing that Auto-Encoders and RBMs may be viewed as two different ways to derive training criteria for forming the same type of analytically defined energy landscape.
The view of the Auto-Encoder as a dynamical system allows us to understand how an energy function may be derived for the Auto-Encoder. This makes it possible to assign energies to Auto-Encoders with many different types of activation functions and outputs, and consider minimanization of reconstruction errors as energy minimanization(Kamyshanska, H., & Memisevic, R., 2014).
When trained with some regularization terms, the Auto-Encoders have the ability to learn an energy manifold without supervision or negative examples(Zhao, J., et al., 2016). This means that even when an energy-based Auto-Encoding model is trained to reconstruct a real sample, the model contributes to discovering the data manifold by itself.
This library provides energy-based Auto-Encoders such as Contractive Convolutional Auto-Encoder(Rifai, S., et al., 2011), Repelling Convolutional Auto-Encoder(Zhao, J., et al., 2016), Denoising Auto-Encoders(Bengio, Y., et al., 2013), and Ladder Networks(Valpola, H., 2015). But it is more usefull to redescribe the Auto-Encoders in the framework of Generative Adversarial Networks(GANs)(Goodfellow, I., et al., 2014) to make those models function as not only energy-based models but also Generative models. For instance, theory of an Adversarial Auto-Encoders(AAEs)(Makhzani, A., et al., 2015) and energy-based GANs(EBGANs)(Zhao, J., et al., 2016) enables us to turn Auto-Encoders into a Generative models which referes energy functions.
The Generative Adversarial Networks(GANs) (Goodfellow et al., 2014) framework establishes a
min-max adversarial game between two neural networks – a generative model, G, and a discriminative
model, D. The discriminator model, D(x), is a neural network that computes the probability that
a observed data point x in data space is a sample from the data distribution (positive samples) that we are trying to model, rather than a sample from our generative model (negative samples). Concurrently, the generator uses a function G(z) that maps samples z from the prior p(z) to the data space. G(z) is trained to maximally confuse the discriminator into believing that samples it generates come from the data distribution. The generator is trained by leveraging the gradient of D(x) w.r.t. x, and using that to modify its parameters.
The Conditional GANs (or cGANs) is a simple extension of the basic GAN model which allows the model to condition on external information. This makes it possible to engage the learned generative model in different "modes" by providing it with different contextual information (Gauthier, J. 2014).
This model can be constructed by simply feeding the data, y, to condition on to both the generator and discriminator. In an unconditioned generative model, because the maps samples z from the prior p(z) are drawn from uniform or normal distribution, there is no control on modes of the data being generated. On the other hand, it is possible to direct the data generation process by conditioning the model on additional information (Mirza, M., & Osindero, S. 2014).
This library also provides the Adversarial Auto-Encoders(AAEs), which is a probabilistic Auto-Encoder that uses GANs to perform variational inference by matching the aggregated posterior of the feature points in hidden layer of the Auto-Encoder with an arbitrary prior distribution(Makhzani, A., et al., 2015). Matching the aggregated posterior to the prior ensures that generating from any part of prior space results in meaningful samples. As a result, the decoder of the Adversarial Auto-Encoder learns a deep generative model that maps the imposed prior to the data distribution.

Reusing the Auto-Encoders, this library introduces the Energy-based Generative Adversarial Network (EBGAN) model(Zhao, J., et al., 2016) which views the discriminator as an energy function that attributes low energies to the regions near the data manifold and higher energies to other regions. THe Auto-Encoders have traditionally been used to represent energy-based models. When trained with some regularization terms, the Auto-Encoders have the ability to learn an energy manifold without supervision or negative examples. This means that even when an energy-based Auto-Encoding model is trained to reconstruct a real sample, the model contributes to discovering the data manifold by itself.

This library models the Energy-based Adversarial-Auto-Encoder(EBAAE) by structural coupling between AAEs and EBGAN. As the prototype is exemplified in demo/Energy-based-Adversarial-Auto-Encoder-for-Representation-Learning.ipynb, the learning algorithm equivalents an adversarial training of AAEs as a generator and EBGAN as a discriminator.
In most classification problems, finding and producing labels for the samples is hard. In many cases plenty of unlabeled data existand it seems obvious that using them should improve the results. For instance, there are plenty of unlabeled images available and in most image classification tasks there are vastly more bits of information in the statistical structure of input images than in their labels.
It is argued here that the reason why unsupervised learning has not been able to improve results is that most current versions are incompatible with supervised learning. The problem is that many un-supervised learning methods try to represent as much information about the original data as possible whereas supervised learning tries to filter out all the information which is irrelevant for the task at hand.
Ladder network is an Auto-Encoder which can discard information Unsupervised learning needs to toleratediscarding information in order to work well with supervised learning. Many unsupervised learning methods are not good at this but one class of models stands out as an exception: hierarchical latent variable models. Unfortunately their derivation can be quite complicated and often involves approximations which compromise their per-formance.
 |  | 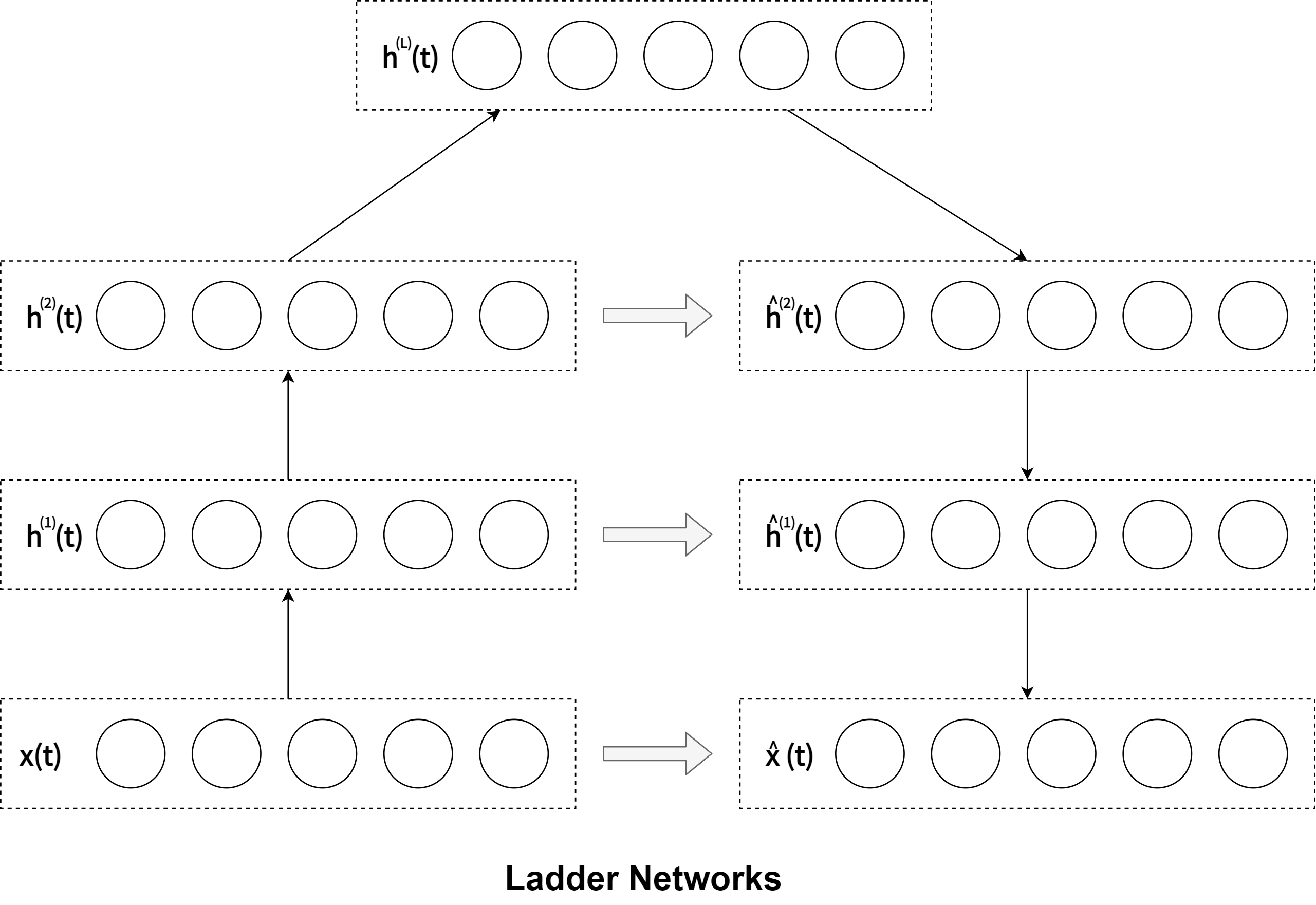 |
| Hierarchical Latent Variable Models | Auto-Encoder | Ladder Networks |
A simpler alternative is offered by Auto-Encoders which also have the benefit of being compatible with standard supervised feedforward networks. They would be a promising candidate for combining supervised and unsupervised learning but unfortunately Auto-Encoders normally correspond to latent variable models with a single layer of stochastic variables, that is, they do not tolerate discarding information.

Ladder network makes it possible to solve that problem by settting recursive derivation of the learning rule with a distributed cost function, building denoisng Auto-Encoder recursively. Normally denoising Auto-Encoders have a fixed input but the cost functions on the higher layers can influence their input mappings and this creates a bias towards PCA-type solutions.
In relation to problem settings such as the Representation Learning, the Ladder Networks is also functionally equivalent of standard CAE as the prototype is exemplified in demo/Convolutional-Ladder-Networks-for-Representation-Learning.ipynb.
Deep Reconstruction-Classification Network(DRCN or DRCNetworks) is a convolutional network that jointly learns two tasks:
Ideally, a discriminative representation should model both the label and the structure of the data. Based on that intuition, Ghifary, M., et al.(2016) hypothesize that a domain-adaptive representation should satisfy two criteria:

The encoding parameters of the DRCN are shared across both tasks, while the decoding parameters are sepa-rated. The aim is that the learned label prediction function can perform well onclassifying images in the target domain thus the data reconstruction can beviewed as an auxiliary task to support the adaptation of the label prediction.
Using this library, for instance, we can extend the Convolutional Auto-Encoder in DRCNetworks to the Convolutional Ladder Networks as mentioned in demo/DRCNetworks-for-Dataset-Bias-Problem.ipynb.
Xu, J., Xiao, L., & López, A. M. (2019) proposed Self-Supervised Domain Adaptation framework. This model learns a domain invariant feature representation by incorporating a pretext learning task which can automatically create labels from target domain images. The pretext and main task such as classification problem, object detection problem, or semantic segmentation problem are learned jointly via multi-task learning.

While DRCNetworks jointly learns supervised source label prediction and unsupervised target data reconstruction, Self-Supervised Domain Adaptation learns supervised label prediction in source domain and unsupervised pretext-task in target domain. DRCNetworks and Self-Supervised Domain Adaptation are alike in not only network structures but also learning algorithms. Neither is mere supervised learning, nor is it mere unsupervised learning. The learning algorithm of DRCNetworks is a semi-supervised learning, but Self-Supervised Domain Adaptation literally does self-supervised learning.
Using this library, for instance, we can extend the Self-Supervised Domain Adaptation as mentioned in demo/Self-Supervised-Domain-Adaptation-for-Classfication-Problem.ipynb and demo/Self-Supervised-Domain-Adaptation-with-Adversarial-training-for-Classfication-Problem.ipynb.
The Reinforcement learning theory presents several issues from a perspective of deep learning theory(Mnih, V., et al. 2013). Firstly, deep learning applications have required large amounts of hand-labelled training data. Reinforcement learning algorithms, on the other hand, must be able to learn from a scalar reward signal that is frequently sparse, noisy and delayed.
The difference between the two theories is not only the type of data but also the timing to be observed. The delay between taking actions and receiving rewards, which can be thousands of timesteps long, seems particularly daunting when compared to the direct association between inputs and targets found in supervised learning.
Another issue is that deep learning algorithms assume the data samples to be independent, while in reinforcement learning one typically encounters sequences of highly correlated states. Furthermore, in Reinforcement learning, the data distribution changes as the algorithm learns new behaviours, presenting aspects of recursive learning, which can be problematic for deep learning methods that assume a fixed underlying distribution.
This library considers problem setteing in which an agent interacts with an environment 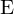 , in a sequence of actions, observations and rewards. At each time-step the agent selects an action at from the set of possible actions,
, in a sequence of actions, observations and rewards. At each time-step the agent selects an action at from the set of possible actions, 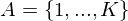 . The state/action-value function is
. The state/action-value function is 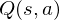 .
.
The goal of the agent is to interact with the by selecting actions in a way that maximises future rewards. We can make the standard assumption that future rewards are discounted by a factor of $\gamma$ per time-step, and define the future discounted return at time 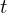 as
as
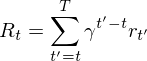 ,
,
where 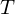 is the time-step at which the agent will reach the goal. This library defines the optimal state/action-value function
is the time-step at which the agent will reach the goal. This library defines the optimal state/action-value function 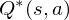 as the maximum expected return achievable by following any strategy, after seeing some state
as the maximum expected return achievable by following any strategy, after seeing some state  and then taking some action
and then taking some action 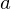 ,
,
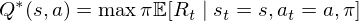 ,
,
where 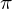 is a policy mapping sequences to actions (or distributions over actions).
is a policy mapping sequences to actions (or distributions over actions).
The optimal state/action-value function obeys an important identity known as the Bellman equation. This is based on the following intuition: if the optimal value 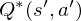 of the sequence
of the sequence 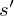 at the next time-step was known for all possible actions
at the next time-step was known for all possible actions 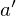 , then the optimal strategy is to select the action maximising the expected value of
, then the optimal strategy is to select the action maximising the expected value of
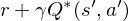 ,
,
 .
.
The basic idea behind many reinforcement learning algorithms is to estimate the state/action-value function, by using the Bellman equation as an iterative update,
 .
.
Such value iteration algorithms converge to the optimal state/action-value function, 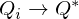 as
as 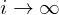 .
.
But increasing the complexity of states/actions is equivalent to increasing the number of combinations of states/actions. If the value function is continuous and granularities of states/actions are extremely fine, the combinatorial explosion will be encountered. In other words, this basic approach is totally impractical, because the state/action-value function is estimated separately for each sequence, without any generalisation. Instead, it is common to use a function approximator to estimate the state/action-value function,
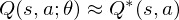
So the Reduction of complexities is required.
In this problem setting, the function of nerual network or deep learning is a function approximation with weights 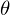 as a Q-Network. A Q-Network can be trained by minimising a loss functions
as a Q-Network. A Q-Network can be trained by minimising a loss functions 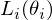 that changes at each iteration
that changes at each iteration 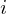 ,
,

where

is the target for iteration and 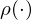 is a so-called behaviour distribution. This is probability distribution over states and actions. The parameters from the previous iteration
is a so-called behaviour distribution. This is probability distribution over states and actions. The parameters from the previous iteration 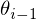 are held fixed when optimising the loss function . Differentiating the loss function with respect to the weights we arrive at the following gradient,
are held fixed when optimising the loss function . Differentiating the loss function with respect to the weights we arrive at the following gradient,

If you pay attention to the calculation speed, it is better to extend the CNN part that is the function approximation to MobileNet. As mentioned in demo/MobileNet-v2-for-Image-Classification.ipynb, this library provides the MobileNet V2(Sandler, M., et al., 2018).
It is not inevitable to functionally reuse CNN as a function approximator. In the above problem setting of generalisation and Combination explosion, for instance, Long Short-Term Memory(LSTM) networks, which is-a special Reccurent Neural Network(RNN) structure, and CNN as a function approximator are functionally equivalent. In the same problem setting, functional equivalents can be functionally replaced. Considering that the feature space of the rewards has the time-series nature, LSTM will be more useful.
The basic concepts, theories, and methods behind this library are described in the following books.

『「AIの民主化」時代の企業内研究開発: 深層学習の「実学」としての機能分析』(Japanese)

『AI vs. ノイズトレーダーとしての投資家たち: 「アルゴリズム戦争」時代の証券投資戦略』(Japanese)

『自然言語処理のバベル: 文書自動要約、文章生成AI、チャットボットの意味論』(Japanese)

『統計的機械学習の根源: 熱力学、量子力学、統計力学における天才物理学者たちの神学的な理念』(Japanese)
Specific references are the following papers and books.
accel-brain-base is a basic library of the Deep Learning for rapid development at low cost. This library makes it possi... Visit Snyk Advisor to see a full health score report for accel-brain-base, including popularity, security, maintenance & community analysis.
The python package accel-brain-base receives a total of 197 weekly downloads. As such, accel-brain-base popularity was classified as limited. Visit the popularity section on Snyk Advisor to see the full health analysis.
We found indications that accel-brain-base is an Inactive project. See the full package health analysis to learn more about the package maintenance status.
While scanning the latest version of accel-brain-base, we found that a security review is needed. A total of 0 vulnerabilities or license issues were detected. See the full security scan results.
Minimize your risk by selecting secure & well maintained open source packages
Scan your application to find vulnerabilities in your: source code, open source dependencies, containers and configuration files
Easily fix your code by leveraging automatically generated PRs
New vulnerabilities are discovered every day. Get notified if your application is affected